Method
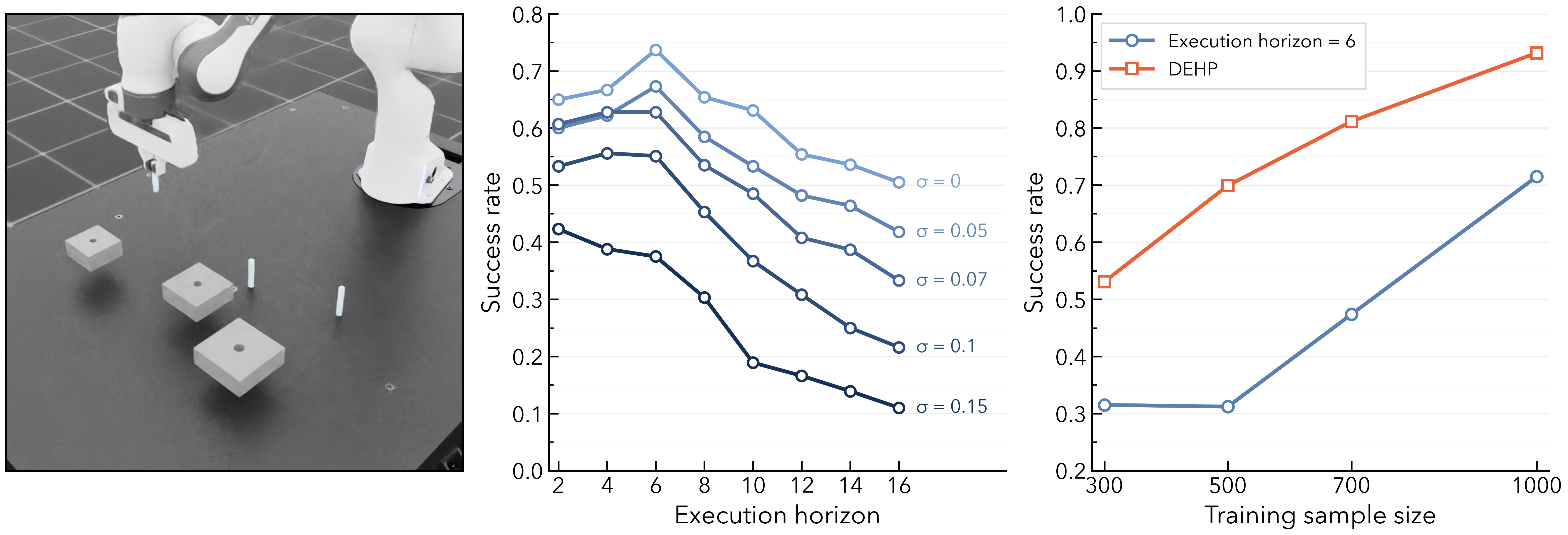
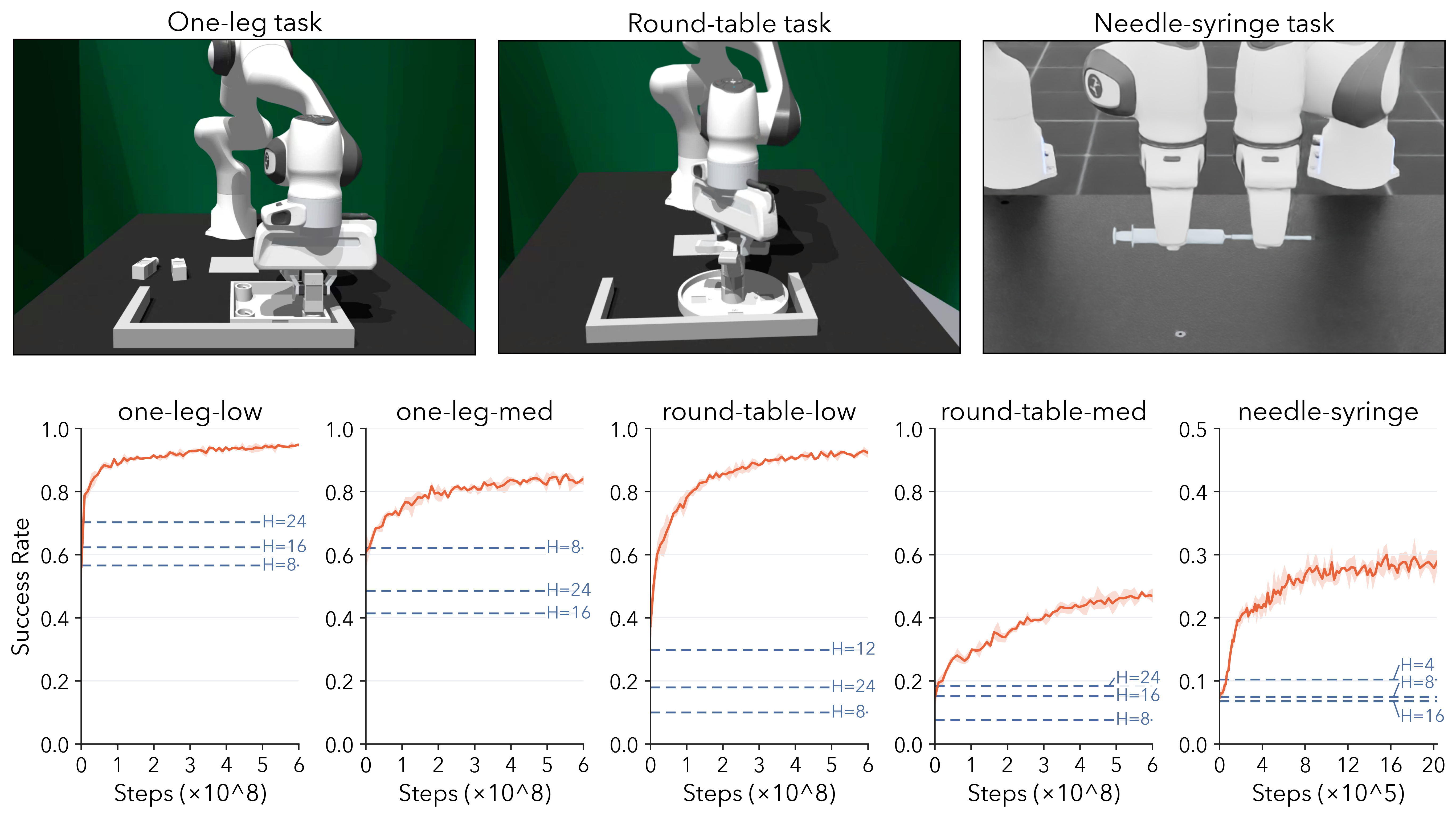
DEHP leaves the base action-chunking policy fixed. At each decision point, the base policy predicts a length-H action chunk, and DEHP samples a categorical execution horizon h in {1, ..., H}. The robot executes only the first h actions and discards the rest before replanning.
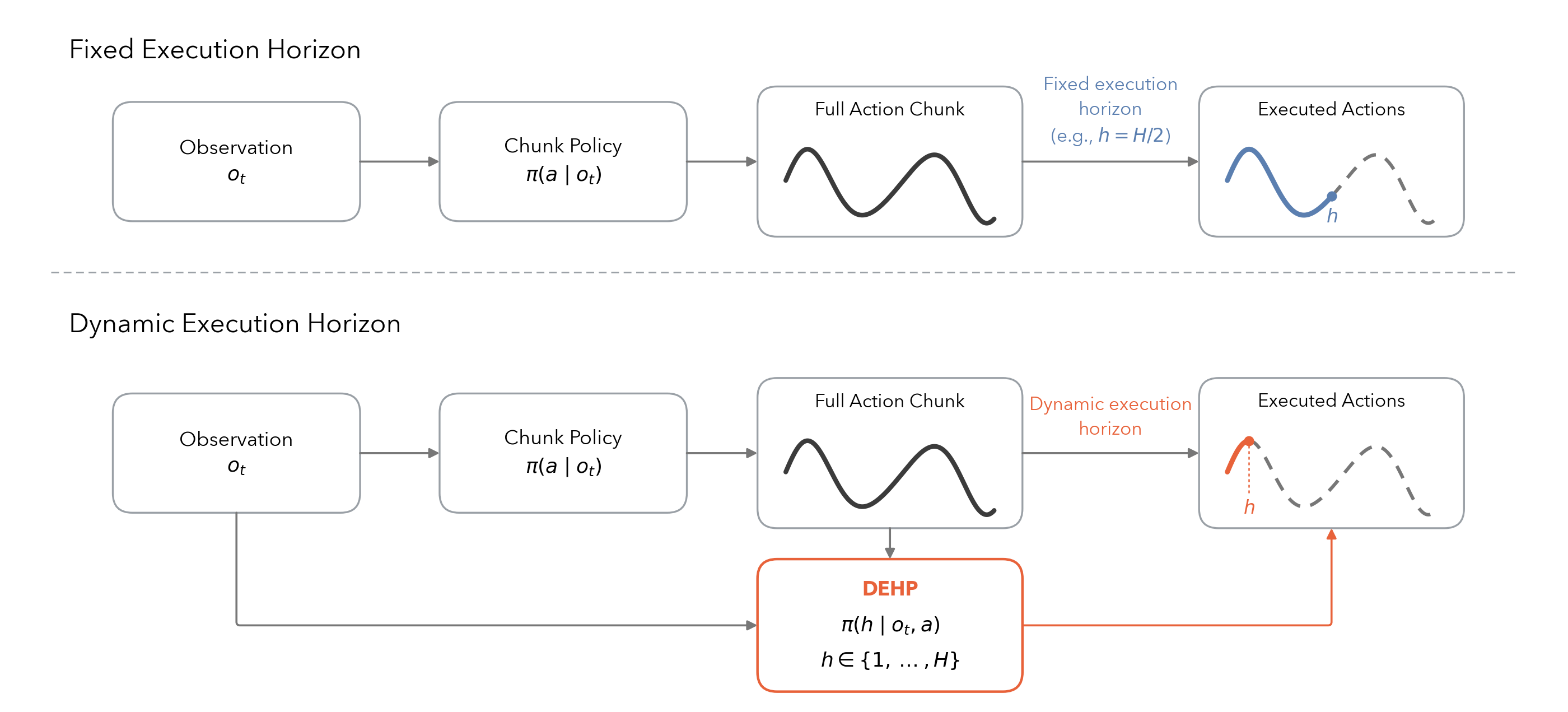
Frozen Base Policy
The action generator is treated as a black box, making the method compatible with pretrained chunk policies such as Diffusion Policy.
Chunk-Level PPO
The horizon head is optimized from sparse task return using a semi-Markov chunk-level PPO formulation.
Adaptive Replanning
Long horizons are used when motion is stable; short horizons are used when contact and alignment require frequent feedback.